Continuous Deployment tramite GitOps


Lo abbiamo giŕ discusso in articoli precedenti ma č importante sottolineare ancora una volta che, nell'epoca moderna, lo sviluppo del codice e soprattutto l'orchestrazione dei rilasci sono diventati notevolmente piů complessi da dover gestire. Nello sviluppo del codice ci sono diversi linguaggi da imparare, sono sempre piů difficili da trovare figure full stack che sanno lavorare sia su framework di backend che su quelli di frontend, poiché ne esistono centinaia e continuano a cambiare di giorno in giorno su entrambi i fronti. Lato deployment model, invece, l'avvento dei microservizi e di applicazioni sempre piů complesse (vedi Netflix, Google etc.), la situazione non č tanto migliore: giŕ a partire dal sistema di versionamento, di gestione delle compatibilitŕ, infrastruttura, sicurezza e cosě via ci sarebbe da scrivere un intero libro.
Nel mondo DevOps, in particolare, ci si concentra principalmente a quelle che sono applicazioni cloud-native, ovvero particolari tipologie di servizi che nascono in cloud e cercano di trarne tutti i vantaggi. Lato tecnico, perň, questo si traduce nell'avere un repository bloccato, in cui tutte le change sono versionate e approvate prima di essere rilasciate, in avere Infrastructure as Code (IaC) con Terraform o altri che permettono di costruire l'infrastruttura e, infine, tutto un sistema di continuous integration e continuous deployment per quanto riguarda la preparazione dei sorgenti e il loro rilascio in un determinato ambiente. La modalitŕ di lavoro "classica" adottata per la maggior parte dei casi oggi, č basata su un modello chiamato "push-based deployments".
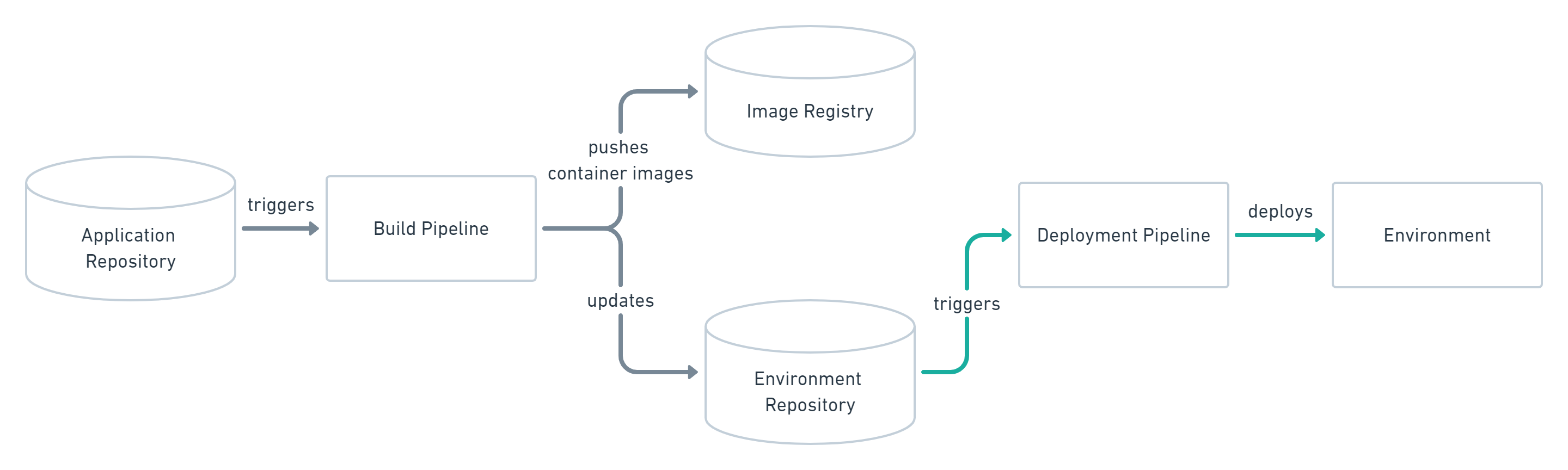
Il codice sorgente, inteso proprio come codice dell'applicazione, codice infrastrutturale, file di configurazione, deployment files di Kubernetes e cosě via, č contenuto all'interno del repository. Ad ogni modifica dello stesso codice, viene invocata una pipeline che verifica le change ed effettua determinati tipi di operazioni in base al contesto. Nel caso di un'applicazione containerizzata, la pipeline compilerŕ i sorgenti e produrrŕ un artefatto, per esempio un'immagine Docker, da pubblicare su un container registry ed eventualmente pubblicherŕ la configurazione della stessa applicazione in uno storage dedicato (esempio le secret su Azure Key Vault, piuttosto che configurazioni in base al cliente/ambiente di destinazione).
Al verificarsi di un cambiamento sul container registry, di una configurazione, oppure nel momento di un rilascio, partirŕ un'altra pipeline di continuous deployment che si occuperŕ di recuperare l'immagine Docker dal container registry, di applicare la configurazione corretta e, infine, di fare il deployment dentro un ambiente desiderato.
Questo modello di rilascio funziona perfettamente, ma funziona fino a quando l'ambiente o il prodotto che stiamo rilasciando č piuttosto piccolo e gestibile. Il problema č che le pipeline sono centrali nell'esecuzione di tutti i processi e, spesso, hanno piů permessi del necessario proprio perché devono gestire tutto il sistema end-to-end. Inoltre, non sempre tutto il processo č automatizzato e, quindi, potrebbero esserci delle deviazioni in produzione rispetto a quello che č il desired state.
In ottica piů moderna, per applicazioni cloud-native, altamente performanti, che hanno necessitŕ di diversi deployment continui ed evitare il piů possibile errori (sia di deployment che eventuali problemi di sicurezza dovuti alle pipeline), invece, si usa un approccio chiamato "pull-based deployment".
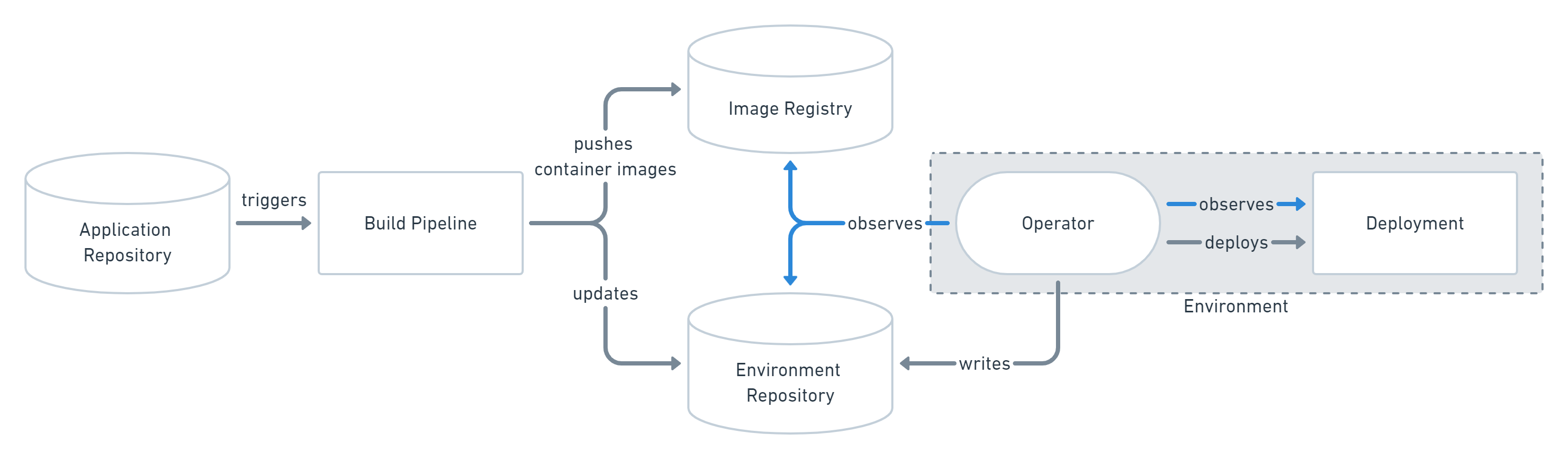
Il risultato finale che si ottiene con un meccanismo di pull-based deployment č identico al precedente. Di fatto, l'immagine di Docker finirŕ sempre per essere caricata dentro l'ambiente di Kubernetes desiderato e avrŕ la configurazione corretta, ma č tutto il sistema che cambia. La fase iniziale č piuttosto simile, nel senso che abbiamo sempre bisogno di un repository dell'applicazione e una pipeline che viene triggerata nel momento in cui si siano verificate modifiche nel codice sorgente, per produrre un artefatto da pubblicare nel container registry.
La parte interessante si sviluppa successivamente. Infatti, il repository che prima conteneva la configurazione dell'ambiente ora contiene quello che serve ad effettuare il rilascio (ad esempio deployment file di Kubernetes, script di installazione etc.) e viene aggiornato automaticamente dalla pipeline. In Kubernetes č stato caricato un operatore, ovvero una specie di servizio che gira in background e resta in ascolto di eventuali modifiche su qualche sistema per effettuare operazioni precise: in questo caso, l'operatore resta in ascolto su modifiche all'interno del repository e, qualora vengano effettuate (e lo saranno automaticamente dalla pipeline), l'operatore si occuperŕ automaticamente di effettuare il deployment, eliminando, di fatto, la gestione delle pipeline che non hanno piů alcun contatto con l'ambiente esterno.
L'operatore che abbiamo menzionato deve necessariamente vivere all'interno del cluster di riferimento per funzionare e lo scopo che gli abbiamo dato č solo per spiegare come cambia il sistema. E' infatti possibile costruire un operatore che, ad esempio, dato un cambio su un repository invia un messaggio su Microsoft Teams per notificare che un deployment č in corso, oppure un operatore che invii una mail in caso in cui il cluster non sia in buono stato (esempio la morte di un nodo).
Il processo inizia a diventare ancor piů interessante quanto vediamo questa cosa da una prospettiva piů ampia e dobbiamo applicare il tutto in scala. Supponendo di avere 100 microservizi, ci ritroveremo, nel caso classico, ad avere 200 repository (100 di applicazioni, 100 di configurazioni) e 200 pipeline (100 di CI, 100 di CD). Nel caso del sistema pull-based, invece, avremo bisogno solo di 101 repository (100 di applicazioni, 1 di configurazione) e 100 pipeline per effettuare la validazione/creazione dell'immagine Docker, mentre per il deployment sarŕ l'operatore di Kubernetes a pensarci. E' chiaramente anche un vantaggio in termini operativi e di costi, poiché ci richiederŕ molto meno tempo di sviluppo e un approccio comune a tutti i team che lavorano allo stesso sistema (infatti, anche le pipeline potrebbero essere semplificate tramite l'uso di template).
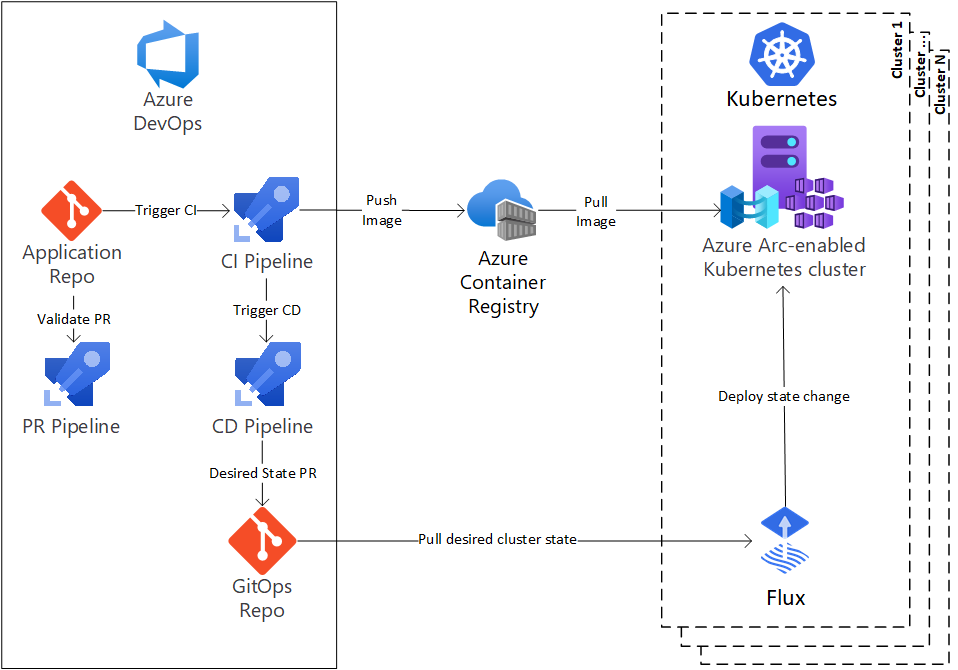
Questa tipologia di deployment mette il repository al centro di tutto, poiché non solo contiene il codice sorgente, ma contiene anche tutte le istruzioni per fare il deployment. Di fatto, questa modalitŕ prendere anche il nome di GitOps, perché, appunto tutto il sistema č basato su git che ha tutta una history e un sistema di tagging per permettere e validare le change.
Tra i principi di GitOps troviamo:
Tutto questo significa che, soprattutto per progetti di larga scala, č possibile avere alta affidabilitŕ per i rilasci, maggiore sicurezza considerando che il sistema non č piů esposto, un sistema unico e centralizzato per fare i deployment e uno stato sempre affidabile che corrisponde al 100% con quello che ci aspettiamo di vedere in produzione, tant'č che puň essere sempre e comunque riproducibile (rendendo ancor piů vero il concetto di Immutable Infrastructure).
All'interno di questo articolo cerchiamo di vedere come poter mettere in pratica tutto il flusso facendo qualche considerazione sui vari aspetti del processo e partendo dalle basi costruendo assieme un microservizio.

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Iscriviti alla nostra newsletter nuoviarticoli per ricevere via e-mail le notifiche!



