Introduzione alla security con GitHub


In un mondo sempre piů orientato ai microservizi, le complessitŕ non aumentano solo in relazione alla capacitŕ di sviluppo, ma sono influenzate anche da tanti fattori diversi fra loro. Tra questi, troviamo ad esempio l'architettura stessa, poiché all'aumentare del numero di servizi crescono i problemi relativi alla manutenzione e il numero di persone coinvolte, la tipologia di strategia di deployment/rilascio in produzione e, ultima ma non per importanza, la sicurezza.
Infatti, negli ultimi anni le enterprise si stanno spostando verso un mondo che basato su GitOps che, per l'appunto, va ad eliminare l'esigenza delle pipeline di continuous deployment. Ma se eliminiamo le pipeline di deployment, come possiamo assicurarci che sia tutto rilasciabile e sicuro? La domanda č molto complessa e cerchiamo di snocciolarne qualche punto nel corso di questo articolo, affrontando qualche tema chiave.
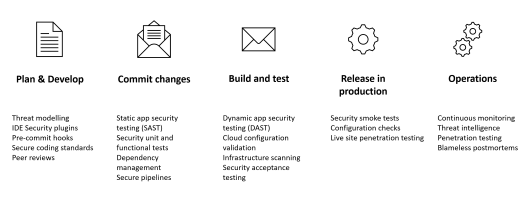
In base alla fase in cui siamo dello sviluppo delle nostre applicazioni, dobbiamo prendere delle accortezze sulla security diverse. Questo, se ci pensiamo, č normale: ci sono infatti molte analisi, come ad esempio un penetration test, che possono essere fatte solo quando il sistema č giŕ preparato – ovvero l'infrastruttura č creata e disponibile, il software č giŕ stato rilasciato – mentre ce ne sono altri che non necessitano nemmeno dei binari delle applicazioni, cosě come nel caso della static code analysis.
Indipendentemente da tutte le strategie evidenziate, quello che deve essere chiaro č che bisogna fare una analisi il prima possibile ed identificare eventuali problemi di sicurezza il prima possibile. Di fatti, se posizioniamo la stessa immagine in un grafico in cui mettiamo in chiaro gli assi del tempo e dei costi, ci troviamo davanti ad una situazione simile.
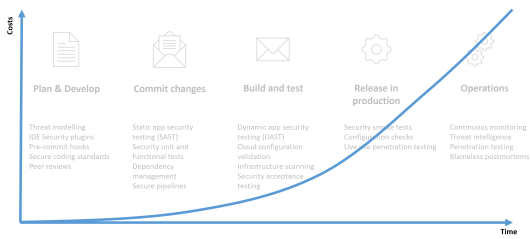
Questo significa semplicemente che prima siamo in grado di identificare potenziali problemi di sicurezza, meno tempo ci metteremo nel risolverli e meno impatto avranno sui clienti e sui costi di risoluzione.
Facendo un esempio pratico: assumiamo di avere un problema con una porta aperta sull'infrastruttura che qualcuno potrebbe sfruttare per avere accesso alla nostra infrastruttura.
Se ce ne accorgiamo in fase di design in un meeting di threat modelling, o perché stiamo analizzando dei documenti sulle best-practice di come costruire un'architettura, la risoluzione sarŕ abbastanza semplice ed immediata, poiché, di fatto, ci sarŕ sufficiente mettere come requisito della feature da sviluppare che la porta deve essere bloccata. Non avremo alcun impatto su chi utilizzerŕ i nostri servizi e non saremo mai esposti in nessun environment a questo problema.
Al contrario, se ci accorgiamo che la porta č aperta nell'infrastruttura in produzione poiché stiamo facendo maintenance o, peggio, perché siamo giŕ stati attaccati da qualcuno che vuole compiere azioni malevole, gli scenari che si aprono sono diversi. Nella migliore delle ipotesi, č necessario ripartire da zero con l'assessment, verificare se č possibile chiudere la porta in questione, procedere al development effettivo e poi seguire tutto il processo fino alla risoluzione nell'environment di produzione. Nello scenario peggiore, invece, potremmo essere effettivamente stati bucati. Oltre ad eseguire tutti gli step dell'altro scenario, č necessario fare assessment per capire a quali dati qualcuno ha avuto accesso, se ha causato danni all'infrastruttura questi devono essere riparati e cosě via. Questo comporta sicuramente una grossa perdita di tempo in piů, ma ha anche delle conseguenze in termini di costo – banalmente le persone che mantengono le infrastrutture devono essere pagate – e degli impatti sui clienti finali, che non sono valutabili a prescindere, ma che possono includere di nuovo costi (legati anche a potenziali cause legali sulle perdite di dati) e indisponibilitŕ del servizio (di nuovo, vedi costi).
Proprio per questi motivi viene coniato il termine DevSecOps, che mette la security al centro di tutto quello che č il mondo DevOps. Oltre ad effettuare analisi manuali, diventa via via piů importante includere dei security check e dei security gate all'interno dei nostri workflow automatici (Azure DevOps, GitHub o altro). Se un problema viene identificato, č fondamentale che le pipeline si blocchino e ci avvisino di conseguenza. A valle anche di quanto detto prima con un esempio pratico, č molto meglio avere falsi positivi che vengono analizzati da un team di esperti, piuttosto che reali problemi in produzione. Inoltre, č vero che le pipeline impiegheranno piů tempo ad essere eseguite rispetto al normale caso senza i check di security, ma č altrettanto vero che ne potremmo pagare le conseguenze successivamente e la velocitŕ del development č sicuramente inferiore, e quindi non giustificabile, a quelle di un sistema completamente automatizzato che porta il codice in un ambiente di produzione sicuro.
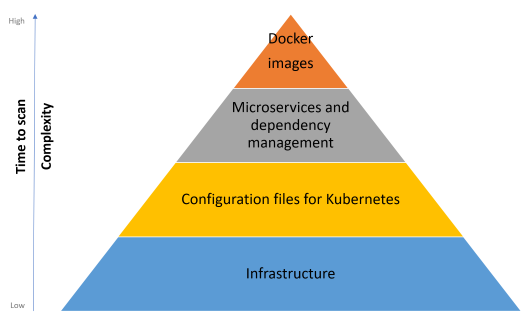
Poiché non abbiamo modo di vedere con un solo articolo il dettaglio di tutti i check di sicurezza che possiamo implementare, cerchiamo di focalizzarci su quattro pillar che si trovano a livelli differenti. Nelle prossime pagine analizzeremo per primo come rendere sicura l'infrastruttura, fino ad arrivare ad installare al suo interno dei microservizi.

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Iscriviti alla nostra newsletter nuoviarticoli per ricevere via e-mail le notifiche!



